Unfinished article
![]()
Distributed set of queues with routing and some consistency guarantees.
Partitioning
In Kafka terms, partition is separate queue. Then you have Topic, which is a group of partitions.
That predefined number of partitions is spread across nodes.
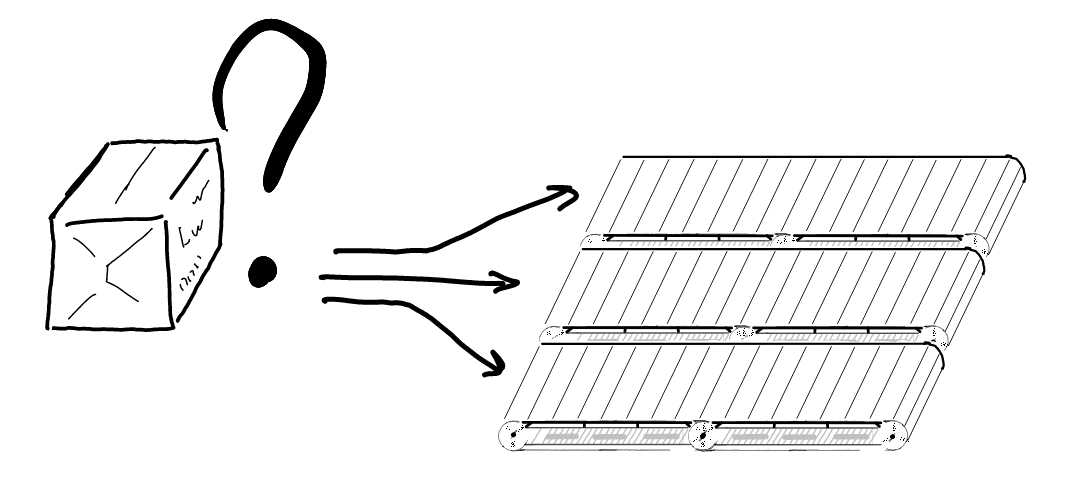
How do we know the partition for each specific message?
Log Segments and Offsets
Each partition is stored as append-only immutable log file.
New messages are appended, replicated, and read by offsets. Old log files are deleted later.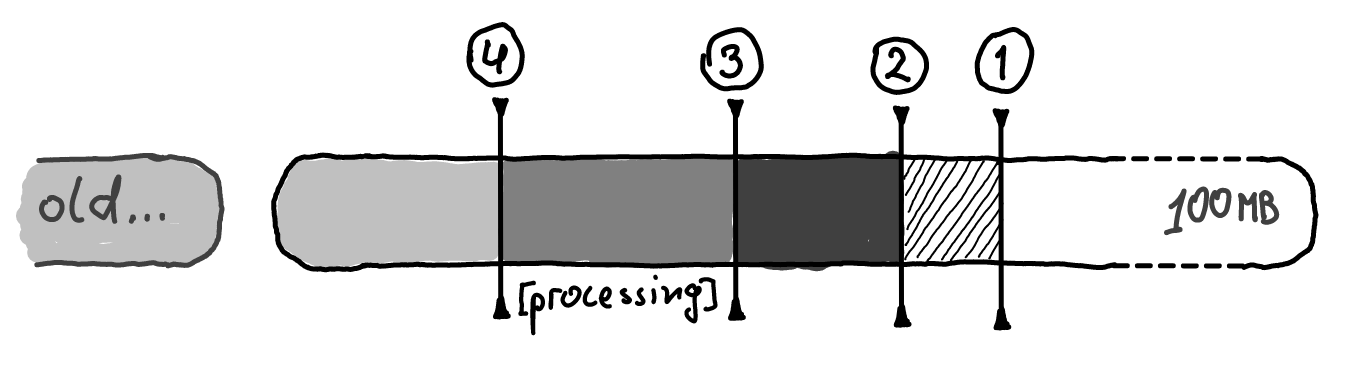
- Current position, where new messages are written;
- “HighWatermark” position that was replicated (if needed);
- Read position
Here your custom software received, process, and commits messages
- Commit position
old log file is deleted after retention window
Once again, Kafka creates log files for each partition separately, so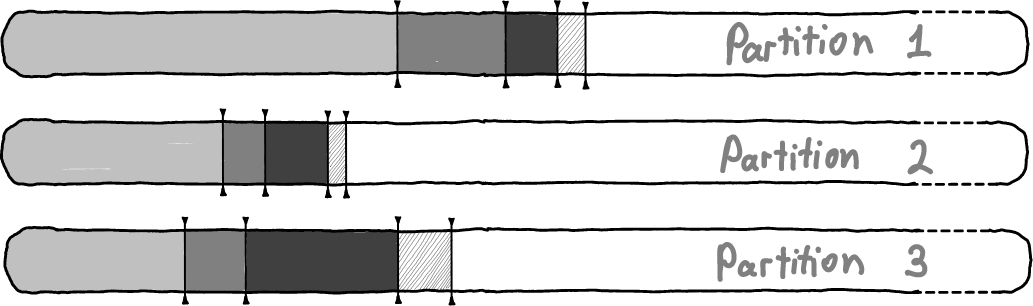
Message Order
Understanding internals, one may ask how does Kafka keeps topic message ordering?![]()
partition = hash(key) % len(patitions)
Usually user_id, transaction_id, content_id or suchlike fields are set as message key.
Consistency
Usually you have to choose between duplicated messages (at least once) or lost messages (at most once)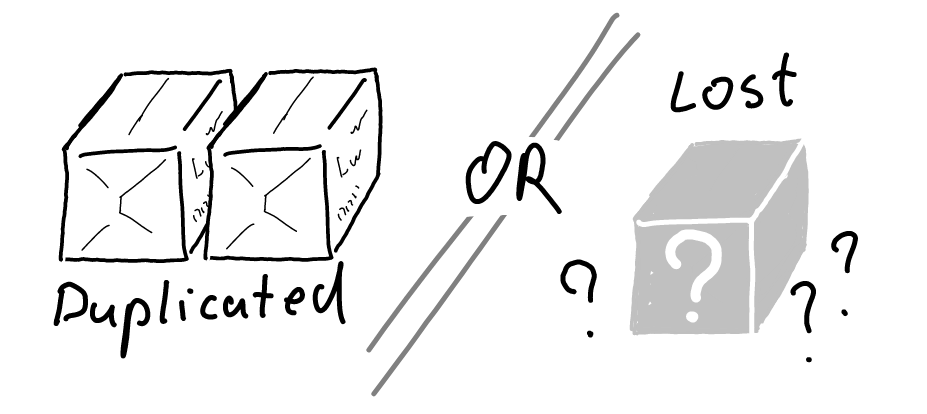
Kafka claims to support “Exactly once” mode, via two phase commit, but that’s a separate topic of discussion.