TBD: diagram
1. Create replication slot
This way, you preserve WAL (new changes) from being deleted. This would also create a snapshot of a current state. Snapshot can be exported, or reused in current transaction.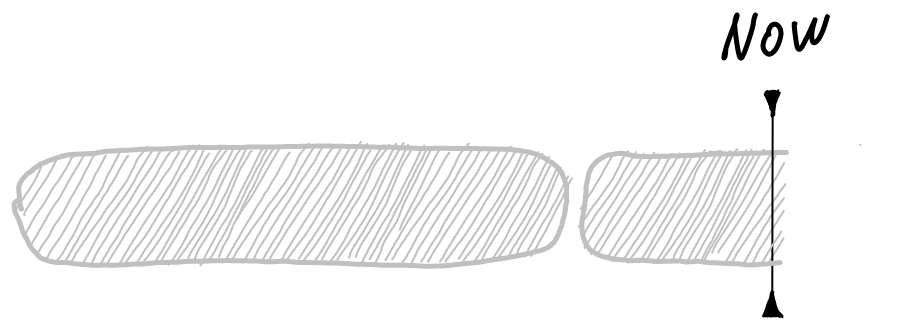
2. Import existing data.
In replication only changes are streamed. Current state needs to be backuped manually.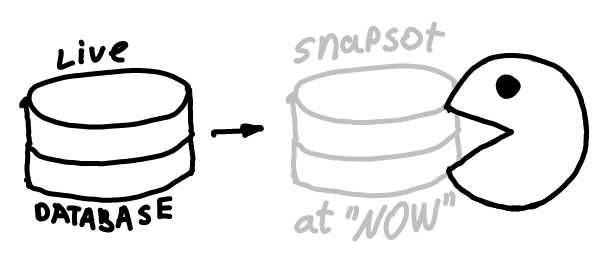
Physical replication:
There is a mechanism to make a backup of a running server, called “base backup”. You need to specify snapshot name, to avoid data races. Base backup is tar archive of current pg_data folder, that can be used as replica initial data.
Logical replication:
Base backup would not work here, but we have a snapshot, that allows us to query DB, using that exact state.
So we fetch all the data in old fashioned way, using COPY foo TO or SELECT FROM foo command.
COPY is prefered, since it’s faster, and is available in simple protocol.
3. Subscribe and Stream changes. Protocol
After START_REPLICATION SLOT command server sends all updates. Format depends of slot. Physical is raw WAL, while Logical depends of decoding plugin, specified it this command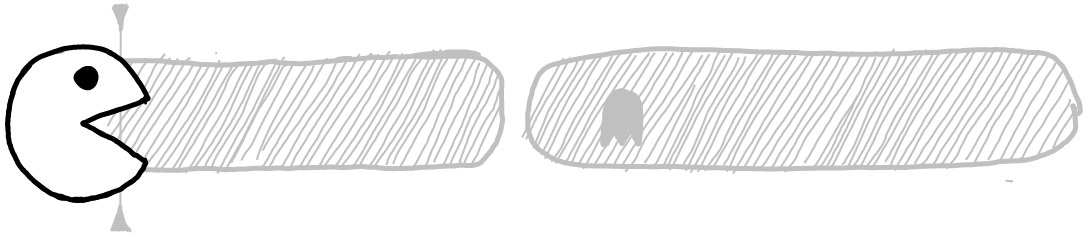
pgoutput for example, uses same encoding as regular query results. Since 14.0 binary encoded rows are also awailable.
4. Always Commit changes
After data was successfuly processed and is no longer needed, update WAL positions via Standby status update message. This would unlock garbage collection of old log files.
5. Resume streaming
After restart (regular, crash, powerloss…)
If slot IS NOT lost:
Goto P3 and continue streaming from last commited position, no additional actions are required.
If slot IS lost:
Clean the data Goto P1, and start from scratch